
Speech Recognition Report
: Analysis on the Market, Trends, and TechnologiesThe speech recognition market is accelerating into specialized, high-value deployments: the market size was *$17.74 billion in 2024 and internal projections indicate growth to $82.98 billion by 2032, reflecting a 21.2% projected CAGR*. This growth is driven by three compounding forces: self-supervised model adoption that lowers data costs and improves low-resource language performance, multimodal and LLM integration that converts transcripts into actionable intelligence, and edge/on-device deployments that meet latency and privacy requirements. Together these shifts push competition away from generic ASR toward domain-embedded systems (healthcare, legal, accessibility, automotive) and a new battleground where companies either build platform-level voice intelligence or win narrow, high-margin niches.
49 days ago, we last updated this report. Notice something that’s not right? Let’s fix it together.
Topic Dominance Index of Speech Recognition
To gauge the influence of Speech Recognition within the technological landscape, the Dominance Index analyzes trends from published articles, newly established companies, and global search activity

Key Activities and Applications
- Clinical and Healthcare Documentation — Real-time transcription and structured EHR entry in clinical workflows remains a top commercial activity, improving clinician throughput and documentation completeness.
- Legal and Professional Dictation — High-accuracy, domain-tuned transcription for legal proceedings and professional documentation continues to be a reliable revenue stream due to its tolerance for premium pricing and integration complexity.
- Accessibility and Non-Standard Speech Support — Enabling people with atypical speech patterns (disorders, age-related changes, heavy accents) to interact with mainstream voice interfaces is a prioritized activity that produces defensible training data and social impact value.
- Contact Center Automation & Voice Analytics — Real-time call transcription, topic detection, sentiment scoring, and compliance tagging are used to reduce handle times and automate quality control for agents.
- Voice Biometrics and Fraud Prevention — Speaker verification and behavioral voice analytics are being embedded into authentication and risk-scoring stacks for financial services and call centers.
- Edge Voice Interfaces for Automotive and IoT — Hands-free automotive assistants and smart-home/IoT voice control require low-latency, privacy-preserving on-device inference to meet regulatory and usability constraints.
- Media Production and Localization — Speech-to-speech, AI dubbing, and synthetic voice production accelerate content localization and reduce production costs in games, film, and advertising.
- Education and Child-Focused Tools — Voice engines specialized for children's speech support reading, language learning, and assessment, creating a school-oriented product category with sticky integrations.
Emergent Trends and Core Insights
- Self-Supervised Learning as a Cost Lever — Adoption of backbones similar to wav2vec 2.0 and Whisper reduces dependency on labelled corpora, making support for low-resource languages and dialects commercially attainable and accelerating model updates.
- Multimodal Rescoring Improves Noisy-Channel Performance — Combining audio with vision (lip-reading) or session context reduces word-error rates in adverse acoustic settings, enabling deployments in noisy industrial and teleconference environments.
- Edge and On-Device Inference Move from Niche to Requirement — On-device models satisfy privacy rules and sub-100 ms latency needs for in-car assistants and medical devices; this is driving investment in quantization, pruning, and specialized SDKs for mobile and embedded silicon.
- From Transcription to Understanding (AUI) — The business value migrates from raw STT to systems that extract actions, summaries, compliance flags, and structured records from voice data; integration of LLMs (or frameworks like LeMUR) with ASR pipelines is the strategic differentiator.
- Verticalized Models Create Durable Moats — Domain-tuned vocabularies and proprietary jargon corpora (medical, legal, radiology) produce measurable accuracy gains and justify premium pricing, making vertical specialization a defensible strategy.
- Generative Voice & Safety Controls — Rapid quality gains in synthetic speech create content workflows but produce regulatory and ethical friction; watermarking and detection tools are emerging as required safety layers Resemble AI.
- Regulatory and Data-Residency Fragmentation Risk — Strict local data rules can fragment global API strategies and favor regional players that own localized training data and residency solutions Speech and Voice Recognition Market Trends 2025.
Technologies and Methodologies
- Transformer / Conformer-based End-to-End Models — Modern acoustic modeling stacks use attention-heavy architectures to jointly model acoustics and sequence dependencies for lower WER across speakers and acoustic conditions.
- Self-Supervised Pretraining + Lightweight Fine-Tuning — Pretrained audio encoders significantly reduce labeled data needs; fine-tuning on domain data produces the accuracy lift required for vertical applications What are the future trends in speech recognition technology.
- Signal-Level Innovations (Separation & Enhancement) — Beamforming, source separation, and neural speech enhancement remain critical for far-field and multi-speaker settings and are frequently implemented as front-end stages prior to ASR.
- On-Device Optimization: Quantization, Pruning, Tiny-NNs — Techniques that reduce memory and compute enable real-time inference on mobile SoCs and microcontrollers, unlocking embedded automotive and IoT use cases.
- Multimodal Fusion Pipelines — Architectures that fuse audio, video (lip cues), and contextual metadata rescore hypotheses and reduce errors in noisy channels The future development trends of speech recognition.
- Hybrid Human-AI Workflows for Critical Accuracy — Combining automated ASR with human-in-the-loop correction (especially in legal and medical transcripts) balances throughput and error budgets while models improve.
- Voice Biometrics & Behavioral Analytics — Acoustic feature sets feed speaker ID, anti-spoofing, and behavioral models used for authentication and risk scoring in BFSI and security contexts.
- LLM-Integrated Voice Intelligence — Pipeline patterns that feed transcriptions into LLMs for summarization, intent extraction, and action generation represent the new product frontier for enterprise voice platforms AssemblyAI.
Speech Recognition Funding
A total of 625 Speech Recognition companies have received funding.
Overall, Speech Recognition companies have raised $18.0B.
Companies within the Speech Recognition domain have secured capital from 2.4K funding rounds.
The chart shows the funding trendline of Speech Recognition companies over the last 5 years
Speech Recognition Companies
- Voiceitt — Voiceitt develops ASR tailored to non-standard speech patterns so people with speech impairments can use mainstream voice products; the company combines custom acoustic models with real-time mapping to canonical speech and operates as a social-impact commercialization, making its dataset and domain expertise hard to replicate.
- SoapBox Labs — SoapBox Labs builds speech engines engineered for children's vocal characteristics and accents, powering assessments and literacy tools; their focus on age-specific datasets and institutional integrations (schools and publishers) gives them product stickiness that generalist ASR providers struggle to match.
- Kanari AI — Kanari AI began with high-accuracy Arabic and dialect models and now delivers end-to-end voice AI stacks for enterprise deployments; their linguistic focus and deployment expertise across sensitive regional markets create a competitive moat where global players underperform without targeted investment.
- FlexSR Limited — FlexSR Limited proposes a signal-centric approach that claims to reduce or eliminate acoustic model retraining by applying linguistic rules directly to raw signals; if validated at scale, this method could collapse adaptation cycles and materially lower time-to-market for new languages and accents.
- Keen Research — Keen Research focuses on on-device ASR SDKs optimized for mobile and embedded silicon, enabling privacy-first voice features in constrained hardware; their small-footprint toolchain targets automotive and embedded OEMs that require deterministic latency and local inference.
Get detailed analytics and profiles on 3.0K companies driving change in Speech Recognition, enabling you to make informed strategic decisions.
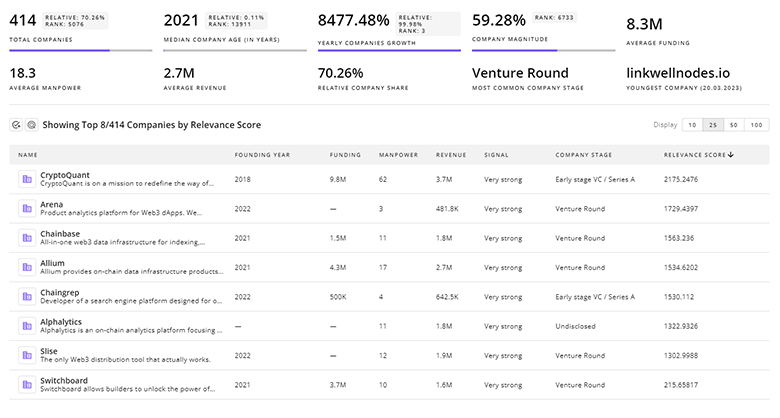
3.0K Speech Recognition Companies
Discover Speech Recognition Companies, their Funding, Manpower, Revenues, Stages, and much more
Speech Recognition Investors
TrendFeedr’s Investors tool provides an extensive overview of 2.8K Speech Recognition investors and their activities. By analyzing funding rounds and market trends, this tool equips you with the knowledge to make strategic investment decisions in the Speech Recognition sector.
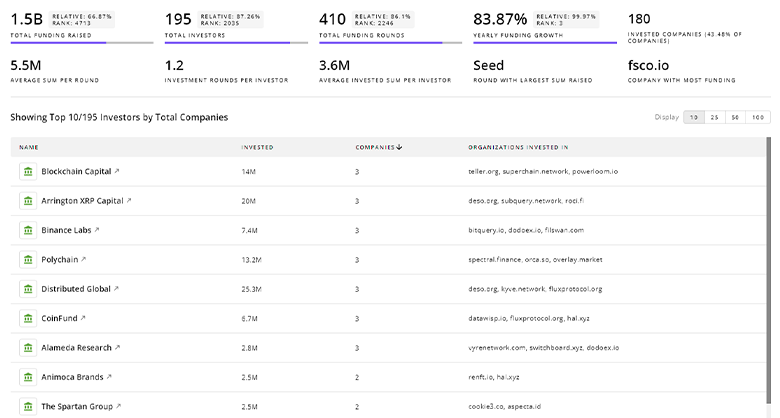
2.8K Speech Recognition Investors
Discover Speech Recognition Investors, Funding Rounds, Invested Amounts, and Funding Growth
Speech Recognition News
Explore the evolution and current state of Speech Recognition with TrendFeedr’s News feature. Access 11.3K Speech Recognition articles that provide comprehensive insights into market trends and technological advancements.
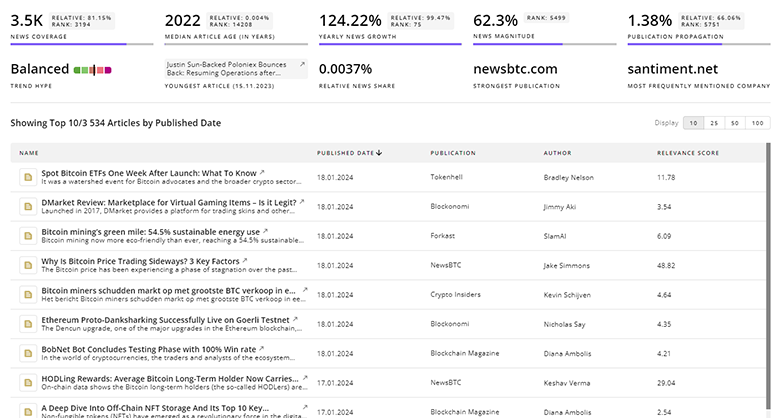
11.3K Speech Recognition News Articles
Discover Latest Speech Recognition Articles, News Magnitude, Publication Propagation, Yearly Growth, and Strongest Publications
Executive Summary
The speech recognition market is moving from a commoditized transcription utility to a landscape defined by domain specialization, privacy-conscious edge inference, and voice-to-action intelligence. Commercial success will accrue to organizations that convert voice signals into structured business outcomes: accurate clinical records, authenticated transactions, actionable contact-center insights, or accessible voice interfaces for underrepresented speakers. Firms should choose between two durable strategies: build platform capabilities that integrate ASR with LLMs and analytics, or invest in narrowly focused data and deployment moats—language/dialect expertise, non-standard speech corpora, or certified on-device SDKs—that resist scale-driven commoditization. Investors and product leaders must prioritize proprietary vertical data, low-latency on-device performance, and content-safety mechanisms for synthetic voice to capture the next wave of value in voice intelligence.
We're looking to collaborate with knowledgeable insiders to enhance our analysis of trends and tech. Join us!










