
Synthetic Data Report
: Analysis on the Market, Trends, and TechnologiesThe synthetic data market is accelerating from pilot to production-grade adoption as enterprises demand privacy-safe, high-utility substitutes for scarce real datasets; the internal trend data records a 2024 market size of $310,500,000, with projections that position specialized vendors to capture large, industry-specific pools of value by 2030. Market research consensus places near-term CAGR estimates broadly in the 30–40% range, driven by tabular data demand for regulated sectors, escalating computer-vision workloads for autonomy, and enterprise test-data automation coherentmarketinsights – Synthetic Data Market, Coherent Market Insights.
88 days ago, we last updated this report. Notice something that’s not right? Let’s fix it together.
Topic Dominance Index of Synthetic Data
To gauge the influence of Synthetic Data within the technological landscape, the Dominance Index analyzes trends from published articles, newly established companies, and global search activity

Key Activities and Applications
- AI/ML Model Training — Generate labeled datasets at scale to reduce dependency on sensitive production data; enterprises use synthetic samples to enlarge minority classes and shorten iteration cycles.
- Software Test Data Management — Provide consistent, production-like relational and transactional data into CI/CD pipelines to accelerate QA while preserving compliance gminsights - Synthetic Data Generation Market Size - By Data Type.
- Regulatory-Safe Data Sharing (Privacy & Compliance) — Replace or augment patient and financial records with synthetic replicas to enable cross-institution research and third-party analytics under GDPR/HIPAA constraints.
- Computer Vision & Simulation — Produce photorealistic, annotated image/video datasets and sensor streams for autonomous vehicles, robotics and industrial inspection using physics-based renderers plus domain randomization grandviewresearch - Synthetic Data Generation Market Size, Share & Trends Analysis Report.
- Time-Series & Financial Scenario Generation — Create synthetic market paths, yield curves and stress scenarios for risk testing and strategy validation without exposing proprietary transaction records.
- Digital Twins & Edge Simulation — Feed continuous synthetic sensor streams to digital twin infrastructures to validate control systems and reduce physical testing cost.
Emergent Trends and Core Insights
- Shift to Purpose-Conditioned Synthesis — Leading IP and product development focus on conditioned generators that produce datasets constrained to downstream task requirements (schema, edge-cases, regulatory thresholds), improving utility while reducing manual curation.
- Tabular Data Remains a Revenue Anchor — Multiple market studies estimate tabular data as the largest slice (≈35–42% of market) because regulated industries require structure-preserving, referentially coherent synthetic tables.
- Diffusion and Hybrid Pipelines for Visual Fidelity — Diffusion-based and hybrid physics+neural pipelines now outcompete classic GAN-only stacks for high-fidelity image/video synthesis, lifting model transfer performance for vision workloads.
- SaaS + Governance = Enterprise Adoption — Adoption favors SaaS platforms that embed PETs (differential privacy, disclosure risk scoring) and enterprise connectors (Snowflake, Oracle, SAP) as standard capabilities Synthesized platform traction in finance & regulated customers.
- Validation Bottleneck Hardens — As generation quality improves, evaluation—measuring utility vs. disclosure risk—becomes the gating factor; standardized metrics and third-party benchmarks are emerging as procurement requirements Evaluating Synthetic Data — industry brief.
- Regional Diversification — North America leads deployment and funding, while APAC shows the fastest growth rates and rising local vendors targeting compliance-sensitive verticals.
Technologies and Methodologies
- Generative Adversarial Networks (GANs) & VAEs — Workhorses for tabular and some image tasks; many enterprise stacks still operationalize CTGAN/TVAE variants for multi-table synthesis.
- Diffusion Models + Physics Renderers — Combine stochastic denoising models with high-fidelity rendering engines to create labeled visual corpora and simulated sensor outputs for autonomy testing AI Image Generator opportunity analysis.
- Agent-Based & Scenario Simulation — Produce behaviourally coherent time-series and interaction data for mobility, finance and epidemiological studies; ABM enables scenario stress testing at scale Agent-based modeling use in transport & finance.
- Differential Privacy & Risk Engines — Integrated into pipelines to deliver quantifiable privacy budgets and iterative disclosure-risk reduction during synthesis.
- Foundation Models for Time Series — Emerging multi-modal time-series foundation models enable promptable generation of sequential data for forecasting and backtesting Synthefy.
- Open-Core Tooling and Evaluation Suites — Community tools (SDV, SDMetrics) establish reproducible benchmarking and accelerate platform adoption inside enterprises The Synthetic Data Vault (SDV).
Key operational constraint: synthetic pipelines must preserve dimensional integrity (logical cross-field relationships and referential integrity) to be trusted in production workflows; failing that, synthetic data adds risk rather than removing it.
Synthetic Data Funding
A total of 287 Synthetic Data companies have received funding.
Overall, Synthetic Data companies have raised $10.8B.
Companies within the Synthetic Data domain have secured capital from 1.0K funding rounds.
The chart shows the funding trendline of Synthetic Data companies over the last 5 years
Synthetic Data Companies
- GenMD — GenMD generates HIPAA/GDPR-compliant synthetic replicas of EHRs to enable secure sharing and monetization of clinical datasets; the offering targets clinical research teams that require high statistical fidelity for trial augmentation while avoiding PHI transfer (small, focused team).
- Nuvanitic — Nuvanitic builds an intelligent platform that blends digital twin intelligence, small language models and privacy-first synthetic data to support device and drug development workflows; it emphasizes context-aware simulation for clinical decision support and regulatory use cases.
- Synthera AI — Synthera AI focuses on synthetic financial markets: yield curves, equities and FX scenarios for portfolio stress testing and strategy validation, capturing non-linear correlations that classical Monte Carlo methods miss; the firm targets quant desks and risk teams with scenario-rich simulation products.
- AgriSynth — AgriSynth produces pixel-accurate synthetic crop-scene imagery annotated at scale to train agricultural vision and robotic systems; by delivering perfect labels for rare lesion patterns and high-resolution plant phenotypes, it removes a critical dataset bottleneck for precision farming robotics.
- DataCebo — DataCebo commercializes the SDV open-core toolkit into an enterprise product that enables organizations to build in-house generative models for relational and time-series data, appealing to teams that require self-sovereign synthetic pipelines and auditability rather than closed SaaS locks.
Get detailed analytics and profiles on 1.0K companies driving change in Synthetic Data, enabling you to make informed strategic decisions.
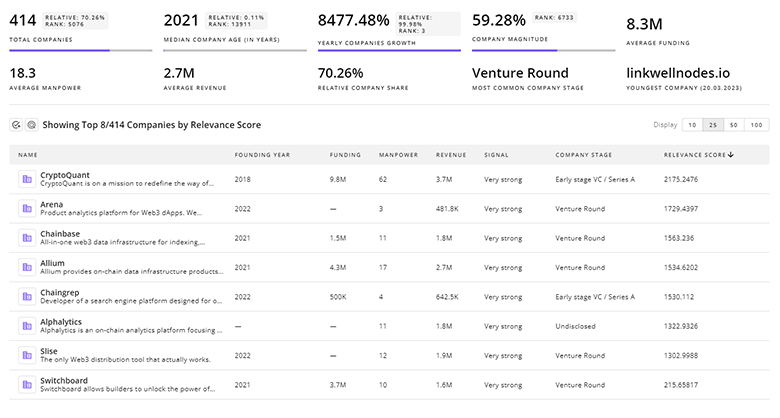
1.0K Synthetic Data Companies
Discover Synthetic Data Companies, their Funding, Manpower, Revenues, Stages, and much more
Synthetic Data Investors
TrendFeedr’s Investors tool provides an extensive overview of 1.4K Synthetic Data investors and their activities. By analyzing funding rounds and market trends, this tool equips you with the knowledge to make strategic investment decisions in the Synthetic Data sector.
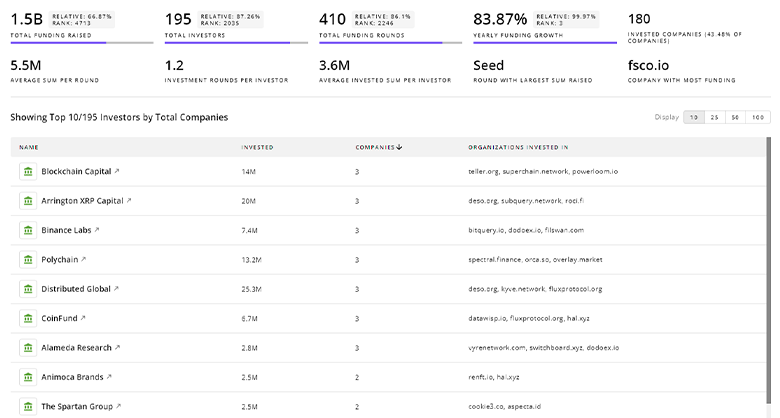
1.4K Synthetic Data Investors
Discover Synthetic Data Investors, Funding Rounds, Invested Amounts, and Funding Growth
Synthetic Data News
Explore the evolution and current state of Synthetic Data with TrendFeedr’s News feature. Access 3.5K Synthetic Data articles that provide comprehensive insights into market trends and technological advancements.
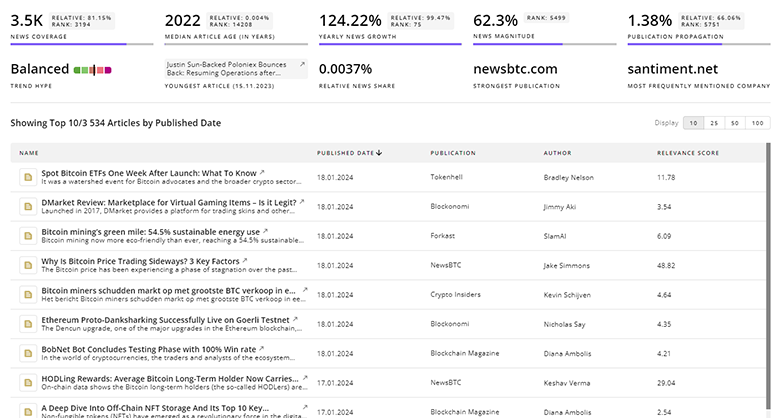
3.5K Synthetic Data News Articles
Discover Latest Synthetic Data Articles, News Magnitude, Publication Propagation, Yearly Growth, and Strongest Publications
Executive Summary
Synthetic data moves from a niche privacy workaround to a foundational data strategy for AI and engineering teams, with growth driven by tabular enterprise needs, vision AI for autonomy, and regulated research workflows. Vendors that pair high utility (task-conditioned fidelity), auditable privacy guarantees, and seamless integration into engineering pipelines will capture the enterprise premium. Equally, organizations that adopt rigorous evaluation and governance—embedding disclosure-risk scoring and representational checks—will convert synthetic datasets into reliable production artifacts rather than one-off experiments. Strategic priorities for the business community: invest in validated generation + evaluation stacks, prefer vendor offerings that demonstrate task performance rather than visual realism alone, and align synthetic pipelines with compliance audit trails to accelerate cross-organizational data collaboration.
We're looking to collaborate with knowledgeable insiders to enhance our analysis of trends and tech. Join us!










