
Data Lakehouse Report
: Analysis on the Market, Trends, and TechnologiesThe data lakehouse market is moving from concept to commercial scale: 2024 market sizing from core trend analysis shows $8.50B and a projected CAGR of 21.9%, signaling rapid growth toward a $22.97B market by 2029. This growth is being driven by enterprises consolidating analytics stacks for AI/ML readiness, rising demand for continuous ingestion and incremental processing, and a vendor ecosystem that is shifting value capture from basic storage to query performance, governance, and cost governance
We updated this report 60 days ago. Noticed something’s off? Let’s make it right together — reach out!
Topic Dominance Index of Data Lakehouse
The Topic Dominance Index trendline combines the share of voice distributions of Data Lakehouse from 3 data sources: published articles, founded companies, and global search

Key Activities and Applications
- Unified analytics across structured and unstructured sources: Lakehouses provide a single access plane for BI, data science, and ML workloads, allowing enterprises to run SQL, Python, and model training on the same data store.
- Real-time streaming ingestion and incremental ELT: Continuous, minute-level freshness and stream-batch integration are now baseline expectations for operational analytics and feature-store pipelines
- Query acceleration and high-concurrency serving: Specialized compute engines and runtime accelerators are being deployed to serve interactive analytics and customer-facing applications without copying data into separate warehouses
- Data governance, lineage, and observability: Automated quality checks, metadata-driven access control, and observability stacks protect model inputs and support regulatory reporting in finance and healthcare
- AI/ML feature preparation and LLM data plumbing: Extraction, indexing, and vector-ready processing are emerging as first-class lakehouse activities to feed LLM and retrieval-augmented systems
- Industry vertical deployments: Pre-built, vertical-specific lakehouses (legal, lending, manufacturing) reduce time-to-value by combining domain schemas, governance, and reporting templates
Emergent Trends and Core Insights
- Open table formats are commoditizing the storage layer. Interoperability around Apache Iceberg, Delta Lake, and Hudi is forcing vendors to compete on management, query performance, and cost controls rather than proprietary file formats.
- Cost governance is shifting to FinOps for analytics. Vendors and third-party tools are appearing that provide AI-driven spend optimization and tiered storage policies to control run-time compute spend as the dominant commercial battleground marketresearch - Data Lake Market Report, 2025.
- Federated and virtual lakehouses are rising. Patent and product activity indicate a countertrend where data sovereignty or scale makes physical consolidation infeasible, so virtual unified views and advanced metadata stitching are becoming strategic alternatives.
- Verticalized, packaged lakehouses lower adoption friction. Industry-specific stacks (legal, lending, energy) with pre-mapped schemas and compliance workflows accelerate deployments and create defensible revenue streams for niche vendors Gestalt.
- Incremental and streaming-first compute is a performance multiplier. Incremental SQL evaluation and view maintenance reduce recompute costs and latency for production analytics and online features onehouse.ai.
Technologies and Methodologies
- Open table formats: Apache Iceberg, Delta Lake, Apache Hudi provide ACID semantics, time travel, and schema evolution that enable enterprise governance on object storage.
- High-performance, cloud-native compute engines: Rust-native and purpose-built engines aim to reduce compute cost and latency (examples include LakeSail's Sail framework and StarRocks-powered offerings) LakeSail.
- Incremental computing and materialized-view maintenance: Engines that support incremental evaluation of arbitrary SQL reduce recompute and enable sub-second freshness for downstream applications.
- Metadata-driven automation and declarative pipelines: Declarative YAML pipelines and metadata-first code generation (DataOps, DBT-like patterns) speed onboarding and improve reproducibility starlake.ai.
- Streaming and RAG plumbing for LLMs: Streaming ETL that produces indexed, vector-ready artifacts for retrieval-augmented model workflows links raw telemetry to generative AI use cases.
- Automated governance and observability: Data quality platforms and policy-as-code implement continuous lineage, anomaly detection, and remediation to protect model trust and compliance DQLabs.
Data Lakehouse Funding
A total of 67 Data Lakehouse companies have received funding.
Overall, Data Lakehouse companies have raised $5.5B.
Companies within the Data Lakehouse domain have secured capital from 278 funding rounds.
The chart shows the funding trendline of Data Lakehouse companies over the last 5 years
Data Lakehouse Companies
- e6data — e6data positions itself as a lakehouse compute engine delivering high-concurrency SQL and AI workloads at substantially lower cost and higher throughput. The company claims 10x faster performance with up to 60% lower costs, and interoperability with multiple table formats and BI tools reduces migration friction for enterprises seeking to keep data in-place. Its traction with enterprise customers highlights demand for compute layers that sit above open storage.
- MovingLake — MovingLake focuses on real-time API consumption and event-driven ingestion to convert pull-based sources into push-based, streaming pipelines. For organizations building operational analytics or event-driven microservices, their API-first integration model shortens the path from source systems to lakehouse-resident datasets.
- Tensorlake — Tensorlake builds streaming ETL and indexing specifically for LLM applications, enabling retrieval-augmented generation through an Indexify engine that transforms raw, unstructured inputs into queryable knowledge artifacts. This specialization addresses the data plumbing gap between enterprise lakes and generative AI workloads.
- Entegrata — Entegrata delivers a turnkey lakehouse that targets law firms, combining secure Azure deployments with pre-mapped legal ontologies and dashboards for practice analytics and compliance. Their verticalized approach demonstrates how pre-packaged domain logic accelerates adoption in regulated professional services.
- Feldera — Feldera provides an incremental compute engine able to maintain complex SQL incrementally, reducing full recomputes and cutting cloud spend by a cited margin. This capability is meaningful for teams that must keep materialized layers highly fresh while controlling operating cost.
Gain a better understanding of 429 companies that drive Data Lakehouse, how mature and well-funded these companies are.
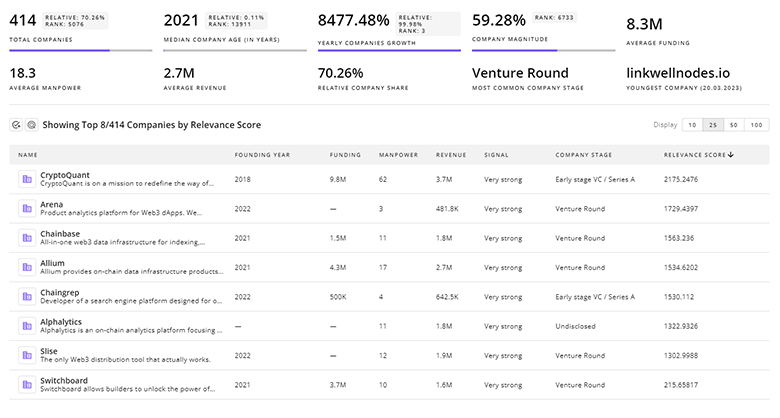
429 Data Lakehouse Companies
Discover Data Lakehouse Companies, their Funding, Manpower, Revenues, Stages, and much more
Data Lakehouse Investors
Gain insights into 455 Data Lakehouse investors and investment deals. TrendFeedr’s investors tool presents an overview of investment trends and activities, helping create better investment strategies and partnerships.
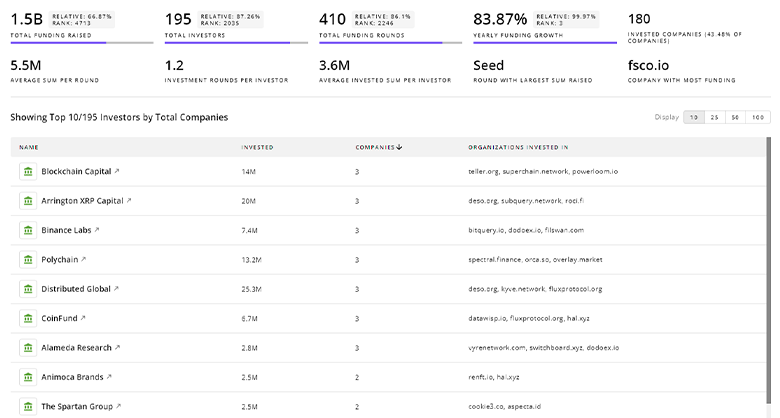
455 Data Lakehouse Investors
Discover Data Lakehouse Investors, Funding Rounds, Invested Amounts, and Funding Growth
Data Lakehouse News
Gain a competitive advantage with access to 1.3K Data Lakehouse articles with TrendFeedr's News feature. The tool offers an extensive database of articles covering recent trends and past events in Data Lakehouse. This enables innovators and market leaders to make well-informed fact-based decisions.
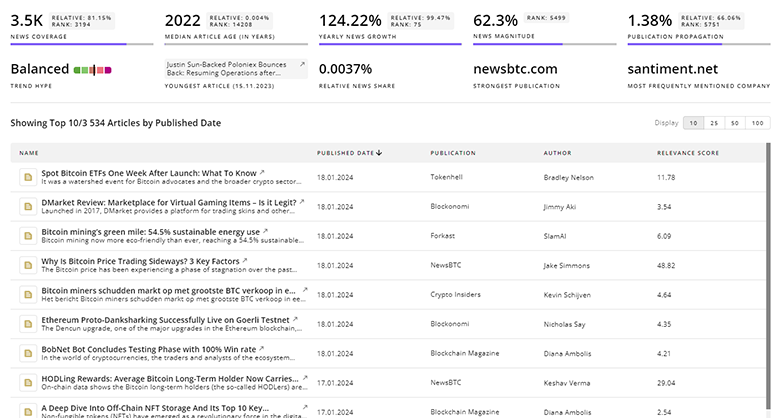
1.3K Data Lakehouse News Articles
Discover Latest Data Lakehouse Articles, News Magnitude, Publication Propagation, Yearly Growth, and Strongest Publications
Executive Summary
The data lakehouse is shifting from an architecture concept to a set of competitive playbooks: storage formats have become broadly interoperable, so differentiation now sits in compute efficiency, incremental processing, cost governance, and domain packaging. Market evidence supports sustained double-digit growth, but the battleground for commercial advantage will be proven reduction in total cost to serve analytics and AI workloads and the ability to enforce enterprise-grade governance automatically. For strategic buyers, the practical priorities are to adopt open table formats, require measurable FinOps controls, and pilot incremental compute or runtime acceleration on high-value use cases before wholesale platform migration. For vendors, embedding deeply into the operational workflows of verticals or delivering unmistakable TCO and latency improvements will determine who moves from niche vendor to platform indispensable.
We seek partnerships with industry experts to deliver actionable insights into trends and tech. Interested? Let us know!










